DB Design
Physical Database Design
- Data compression techniques
- Data Striping (RAID)
- What is RAID and what are different types of RAID configurations?
- RAID stands for Redundant Array of Inexpensive Disks, used to provide fault tolerance to database servers. There are six RAID levels 0 through 5 offering different levels of performance, fault-tolerance.
- Mirroring
- Security
- Permissioning - Users & Groups
Normalization
- Intro to Normalization
- http://www.bkent.net/Doc/simple5.htm
What is Normalization?
- process to eliminate data redundancy, and to remove potential update inconsistencies which arise from inserting, modifying, and deleting data.
- The goal of normalization is to create a set of relational tables that are free of redundant data and that can be consistently and correctly modified. This means that all tables in a relational database should be in the third normal form (3NF).
1st Normal Form
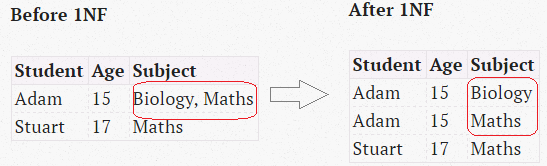
- No multi-value columns
- A relational table, by definition, is in first normal form.
- 1NF requires all values of the columns to be atomic. That is, they contain no repeating values like comma-separated names.
- Table in 1NF contains redundancy of data. Redundancy causes what is called as Update anomalies
2nd Normal Form
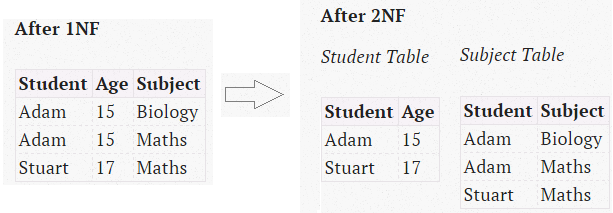
- No partial dependencies
- any non-key columns must depend on the entire primary key. In the case of a composite primary key, this means that a non-key column cannot depend on only part of the composite key.
3rd Normal Form
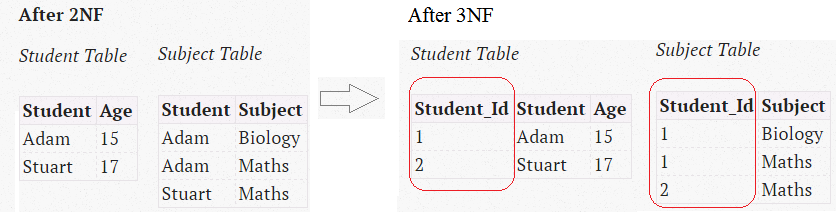
- No transitive dependencies
- 3NF requires that every non-prime attribute must be dependent on primary key.
- Tables violate the 3NF when one column depends on another column, which in turn depends on the primary key (a transitive dependency). One way to identify transitive dependencies is to look at your table and see if any columns would require updating if another column in the table was updated. If such a column exists, it probably violates 3NF.
- A relational table is in 3NF if and only if all non-key columns are
- (a) mutually independent (means that no non-key column is dependent upon any combination of the other columns.)
- (b) fully dependent upon the primary key.
- The first two normal forms are intermediate steps to achieve the goal of having all tables in 3NF. In order to better understand the 2NF and higher forms, it is necessary to understand the concepts of functional dependencies and lossless decomposition.
4th Normal Form: Every non-trivial multivalued dependency in the table is a dependency on a superkey.
5th Normal Form: Every non-trivial join dependency in the table is implied by the superkeys of the table.
- Denormalization
Denormalization for performance
Concept of Time in Database
Temporal Data Types
- Instant: something happened at an instant of time. (e.g., now)
- Interval
- a length of time (e.g., three months)
- The individual units (months, hours, microseconds, etc.) are termed granules
- An interval is relative; an instant is absolute
- An interval can be added to an instant, yielding another instant
- The distance between two instants is an interval
- Unlike instants, intervals have direction. e.g., -7 days
- Year-Month Intervals - store only year, or only month or year-month.
- Day-Time Intervals
- SQL Data types
- DATE
- TIME
- TIME WITH TIME ZONE
- TIMESTAMP - date + time
- TIMESTAMP WITH TIME ZONE - includes date, time and an explicit offset from UTC. e.g.,
11:08:27.123456-07:00, where-07:00indicates 7 hours behind UTC
- Period: an anchored duration of time (e.g., the fall semester, Aug 24 through Dec 18, 1998)
SQL-92 supports instance and intervals only
Kinds of Time
- (1) User-defined time: an uninterpreted time value
- (2) Valid time: when a fact was true in the modeled reality (VALID_FROM, VALID_TO)
-
(3) Transaction time: when a fact was stored in the database (CREATION_TIME, UPDATE_TIME)
- These kinds of time are orthogonal: a table can be associated with none, one, two, or even all three kinds of time. Understanding each kind of time and determining which is present in an application is absolutely critical.
SQL-92 supports only ‘user-defined time’
- Temporal Statements
- Current: now (what is now?)
- Sequenced: at each instant of time (what was, and when?)
- Nonsequenced: ignoring time (what was, at any time?)
Temporal Table Types
- Valid-Time State tables
- Valid-time tables capture a history of validity
- contains
FROM_DATE&TO_DATE - To indicate an active record
TO_DATEis set tonullor end-of-time9999-12-31 - The first consequence of adding valid-time support to a table is that the primary key of such tables needs to take the timestamp into consideration, so that the record is unique at any point in time.
- Transcation-Time State tables
- Transaction-time tables capture a history of the changing state of a table.
- contains information when a record was created and last updated.
- one of these pairs is used
START_DATE&END_DATEIN_Z&OUT_ZCR_TIME&UPD_TIME
END_DATE = '9999-12-31'indicates an active record- rows are logically deleted, because physically deleting old rows would prevent past states from being reconstructed. A table that can be reconstructed as of a previous date is termed a transaction-time state table, as it captures the transactions applied to the table.
- Bi-Temporal Tables
- captures both validity and transaction time of a record
- MarkLogic NoSQL database has a native support for bitemporal collections
- Temporal Tables have also been called historical tables but this implies that they record information only about the past. However, valid-time tables often store information about future.
- The presence of a
DATEcolumn will not render the database as a temporal database; rather, the database must record the time-varying nature of the information managed by the enterprise.
Time-Series Databases
…
Patterns
- How do you implement 1-to-1, 1-to-many and many-to-many relationships while designing tables?
- 1-to-1 relationship can be implemented as a single table and rarely as two tables with primary and foreign key relationships.
- 1-to-Many relationships are implemented by splitting the data into two tables with primary key and foreign key relationships.
- Many-to-Many relationships are implemented using a junction table with the keys from both the tables forming the composite primary key of the junction table.
Schema Patterns
- Data Warehouse schema types - http://datawarehouse4u.info/Data-Warehouse-Schema-Architecture.html
- Star schema
Anti-Patterns
Logical Database Anti-patterns
Comma separated lists (Jaywalking)
- Storing composite values in a single columns. Typically comma separated values.
- Cons
- DB cannot ensure referential integrity on this column.
- VARCHAR column will run into length limit issues.
Multi-column attributes
Entity attribute value
- also known as open schema, schemaless, name-value pairs
- Objective
- to support variable attributes for an entity
- different object types have different attributes and hence stored in different tables. When different object types are related, they are considered instances of the same base type, as well as instances of their respective subtypes. We would like to store objects as rows in a single db table to simplify comparisons and calculations over multiple objects. But we also need to allow objects of each subtype to store their respective attribute columns, which may not apply to the base type or to other subtypes. e.g., in a bugs db, base type is Issue, subtypes are Bug and FeatureRequest.
- Cons
- cannot make mandatory attributes
- cannot make default values for missing attributes
- cannot use SQL data types except string. No way of rejecting invalid data.
- cannot enforce referential integrity
- attribute names could be different for each record e.g.,
reported_date,date_reported. One remedy is to declare a foreign key on the attr_name column. - retrieving all attributes of an entity as a single row requires a join for each attribute.
- One must also know the name of all the attributes at the time of writing the query.
- when metadata is fluid, it’s harder to formulate simple queries.
- You must use outer joins because inner joins would cause the query to return no rows if any one of the attributes were not present for an entity.
- as the number of attributes increases, so does the number of joins, and the cost of the query increases exponentially.
- Solutions
- Single Table Inheritance
- store all related types in a one table. e.g., table = Issues
- pros: simple and best suited when you have few subtypes and few subtype-specific attributes, and you need to use a single-table db access pattern like ActiveRecord
- cons:
- may encounter a limit on the number of columns per table
- need to add an extra column to define the subtype of each row
- Concrete Table Inheritance
- every table contains the same attributes that are common to the base type as well as the respective subtype-specific attributes. e.g., table = Bugs, FeatureRequests.
- pros
- prevented from storing a row containing values for attributes that don’t apply to that row’s subtype
- no need for extra attribute to define the subtype for each row
- cons
- when new attribute is added to the set of common attributes, every table needs to be altered
- no way to easily identify which are common attributes and which are not.
- metadata does not tell any logical relationship exists or whether the tables have similarities merely by coincidence
- to search all objects regardless of their subtypes requires combining multiple queries. Remedy: define a view that is the union of the tables, selecting only the common attributes
- Class Table Inheritance
- create a single table for the base type, containing attributes common to all subtypes. Then for each subtype, create another table, with a primary key that also serves as a foreign key to the base table.
- pros:
- easy to search against all subtypes, as long as your search references only the base type’s attributes
- Semistructured Data/Seralized LOB
- when there are many subtypes or must support new attributes frequently, add a JSON data type
- pros
- completely extensible and adding new attributes is seamless
- every row stores a potentially distinct set of attributes, so many subtypes can be supported
- cons
- SQL written to access attributes in such a structure is non-standard
- no foreign key constraints
- Single Table Inheritance
Metadata tribbles
Adjacency List
- storing multi-level hierarchical data like organization chart, threaded discussion and comments, directory structure, etc.
- pros
- Good for use cases where the depth is not more than 2 or 3 and is fixed.
- cons
- It is easy to query one or two levels of the hierarchy by self joins. However, in order to extend the query to any depth, it becomes impossible, since the number of joins in SQL must be fixed.
- Copying the entire hierarchy from database to application for tree creation is highly inefficient.
- Inserting a node in a sub-tree is easy, however deleting a node or an entire sub-tree is difficult. ON DELETE CASCADE modifier can be used.
- If the non-leaf node should be deleted without deleting the children, then all the parent_id needs to be modified.
- Some databases support
WITHkeyword to recursively query hierarchical data.
1 2 3 4 5 6 | |
- Solutions
- Path Enumeration
- Instead of storing parent_id, store the path to each node in unix file path like format in varchar column. E.g., 1/2/4/5.
- pros: Querying ancestors and children is easy. E.g.,
SELECT * FROM Comment c WHERE c.path like '1/4/' - cons: Same problem as the Jaywalking antipattern.
- Nested Sets
- Assigning a number to each node’s left and right children. Kind of like balanced binary tree.
- cons
- Not easily understandable
- Does not support referential integrity
- Useful only when the tree is queried frequently, than modified
- Closure Table
- Creating a separate table to store the relationship of nodes. By far the versatile design for storing tree structures.
- cons
- requires additional table and hence increasing space consumption.
- Path Enumeration
1 2 3 4 5 6 | |
Physical Database Anti-patterns
- ID Required
- Phantom Files
- FLOAT Antipattern
- ENUM Antipattern
- When to use enums?
- when the set of values is unchanging. e.g., days of week, active/inactive, internal/external, etc.
- use metadata when validating against a fixed set of values. use data when validating a fluid set of values.
- Pros:
- storage is compact compared to strings, since only the ordinal number of the string in the enumerated list is stored.
- Cons:
- valid values for a column is stored in metadata of the table. Modifying valid values require change to table definition. Changing table or column definition should be infrequent, and with attention to testing and quality assurance.
- querying current set of valid values is not easy/straight-forward. e.g., for UI drop-downs. Risk of maintaining information in 2 different places.
- making a value obsolete could upset historical data.
- less portability (not all databases support ENUMs)
- Solutions:
- create a lookup table with one for each allowed value and declare a foreign key constraint.
- pros:
- set of permitted values is stored in data, not metadata
- changing data values needs no interruption to the table access, no table/column definition change
- renaming a value is easy
- easy to make a set of values obsolute
- When to use enums?
- Readable Passwords
Query Anti-patterns
- Ambiguous GROUP BY
- HAVING antipattern
- Poor Man’s Search Engine
- Implicit columns in SELECT and INSERT
Application Anti-patterns
- User-supplied SQL
- SQL Injection
- Parameter Façade
- Pseudokey Neat Freak
- Session Coupling
- Phantom Side Effects
References
- Books
- Refactoring Databases
- SQL Anti-Patterns
- Developing time-oriented database applications in SQL
- Sybase Performance and Tuning Guide