Hadoop Ecosystem
Basics
- Hadoop is an open source platform that provides implementations of both the MapReduce and GFS (Google File System) technologies and allows the processing of very large data sets across clusters of low-cost commodity hardware.
- Host Vs. Node
- The terms host or server refer to the physical hardware hosting Hadoop’s various components.
- The term node will refer to the software component comprising a part of the cluster.
- Features
- Hadoop is not a good
- for low-latency queries like websites, real time systems, etc. (HBase on top of Hadoop serves low-latency queries)
- smaller data sets.
- Hadoop tries to co-locate the data with the compute nodes, so data access is fast because it is local. This feature, known as data locality, is at the heart of data processing in Hadoop and is the reason for its good performance.
- MapReduce is able to do this because it is a shared-nothing architecture, meaning that tasks have no dependence on one other
- Hadoop is not a good
- Processing Patterns that work with Hadoop
- Interactive SQL - By dispensing with MapReduce and using a distributed query engine that uses dedicated “always on” daemons (like Impala) or container reuse (like Hive on Tez), it’s possible to achieve low-latency responses for SQL queries on Hadoop while still scaling up to large dataset sizes.
- Iterative processing - Many algorithms—such as those in machine learning are iterative in nature, so it’s much more efficient to hold each intermediate working set in memory, compared to loading from disk on each iteration. The architecture of MapReduce does not allow this, but it’s straightforward with Spark, for example, and it enables a highly exploratory style of working with datasets.
- Stream processing - Streaming systems like Storm, Spark Streaming, or Samza make it possible to run real-time, distributed computations on unbounded streams of data and emit results to Hadoop storage or external systems.
- Search - The Solr search platform can run on a Hadoop cluster, indexing documents as they are added to HDFS, and serving search queries from indexes stored in HDFS.
- Hadoop Components
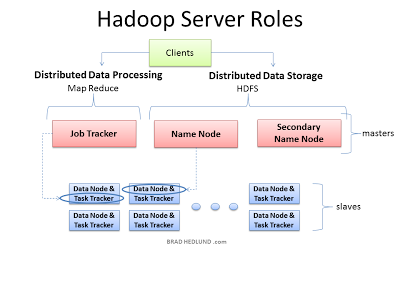
- Hadoop installation consists of four types of nodes
- NameNode + DataNodes - HDFS nodes provide a distributed filesystem
- JobTracker - manages the jobs
- TaskTracker - run tasks that perform parts of the job
- Users submit MapReduce jobs to the JobTracker, which runs each of the Map and Reduce parts of the initial job in TaskTrackers, collects results, and finally emits the results.
- Hadoop installation consists of four types of nodes
| Traditional RDBMS | MapReduce | |
| Data size | Gigabytes | Petabytes |
| Access | Interactive and batch | Batch |
| Updates | Read and write many times | Write once, read many times |
| Transactions | ACID | None |
| Structure | Schema-on-write | Schema-on-read |
| Integrity | High | Low |
| Scaling | Nonlinear | Linear |
HDFS
- distributed filesystem designed to store very large data sets by scaling out across a cluster of hosts.
- optimized for high throughput instead of latency. It achieves high availability through replication instead of redundancy.
- similar to any other linux file system like ext3 - but cannot be mounted - and requires applications to be specially built for it.
- Block size in old file systems are typically 4KB or 8KB of size. In HDFS, it is 64MB to 1GB.
- Replicates each block to multiple machines (default 3) in the cluster. Should the number of copies of a block drop below the configured replication factor, the filesystem automatically makes a new copy from one of the remaining replicas.
- Due to replicated data, failures are easily tolerated.
- not a POSIX-compliant filesystem.
- HDFS is optimized for throughput over latency; it is very efficient at streaming read requests for large files but poor at seek requests for many small ones.
- Pros
- Very larges files - can store files in gigabytes or terabytes in size. A single file can be larger than the size of the disk in a single node.
- Streaming Data Access - HDFS is built around the idea that the most efficient data processing pattern is a write-once, read-many-times pattern.
- Cons
- Not meant for low-latency applications
- Files in HDFS may be written to by a single writer.
- Writes are always made at the end of the file, in append-only fashion. There is no support for multiple writers or for modifications at arbitrary offsets in the file
Concepts
Blocks
- Disk blocks are normally 512 byets. Filesystem blocks are typically few kilobytes. HDFS block is 128MB by default. The blocks are large in HDFS to minimize the cost of disk seeks.
- Unlike in regular filesystem, in HDFS, a 1 MB file stored with a block size of 128 MB uses 1 MB of disk space, not 128 MB
- Why HDFS or a block abstraction for a distributed filesystem?
- a file can be larger than any single disk in the network can be stored in multiple nodes seamlessly.
- Fault tolerance and availability is easier. If a block becomes unavailable, a copy can be read from another location in a way that is transparent to the client.
1
| |
Namenode
- Namenode
- manages the filesystem namespace.
- maintains the filesystem tree and the metadata for all the files and directories in the tree.
- knows the datanodes on which all the blocks for a given file are located; however, it does not store block locations persistently, because this information is reconstructed from datanodes when the system starts.
- This information is stored persistently on the local disk in the form of two files: the namespace image and the edit log.
- Without the namenode, the filesystem cannot be used. In fact, if the machine running the namenode were obliterated, all the files on the filesystem would be lost since there would be no way of knowing how to reconstruct the files from the blocks on the datanodes.
- Each of the blocks comprising a file is stored on multiple nodes within the cluster, and the HDFS NameNode constantly monitors reports sent by each DataNode to ensure that failures have not dropped any block below the desired replication factor. If this does happen, it schedules the addition of another copy within the cluster. (include archictecture diagram from internet)
- To make the namenode resilient to failure, Hadoop provides 2 mechanisms:
- Back up
- back up the files that make up the persistent state of the filesystem metadata.
- Hadoop can be configured so that the namenode writes its persistent state to multiple filesystems.
- These writes are synchronous and atomic.
- The usual configuration choice is to write to local disk as well as a remote NFS mount
- Secondary namenode
- Its main role is to periodically merge the namespace image with the edit log to prevent the edit log from becoming too large.
- usually runs on a separate physical machine because it requires plenty of CPU and as much memory as the namenode to perform the merge. It keeps a copy of the merged namespace image, which can be used in the event of the namenode failing. However, the state of the secondary namenode lags that of the primary, so in the event of total failure of the primary, data loss is almost certain.
- Back up
Datanodes
- store and retrieve blocks when they are told to (by clients or the namenode), and they report back to the namenode periodically with lists of blocks that they are storing.
Block caching
- The blocks from frequently accessed files may be explicitly cached in the datanode’s memory, in an off-heap block cache.
- By default, a block is cached in only one datanode’s memory (configurable on a per-file basis)
- Job schedulers (for MapReduce, Spark, etc.) can take advantage of cached blocks by running tasks on the datanode where a block is cached, for increased read performance.
- Users or applications instruct the namenode which files to cache (and for how long) by adding a cache directive to a cache pool
HDFS Federation
- Since NameNodes keep all the metadata in memory, there is inherent limitation up to which it can scale up. Scaling out with multiple namenodes is called namenode federation
- HDFS federation allows a cluster to scale by adding namenodes, each of which manages a portion of the filesystem namespace. For example, one namenode might manage all the files rooted under
/user, say, and a second namenode might handle files under/share. - To access a federated HDFS cluster, clients use client-side mount tables to map file paths to namenodes. This is managed in configuration using
ViewFileSystemand theviewfs://URIs.
HDFS High Availability
- The combination of replicating namenode metadata on multiple filesystems and using the secondary namenode to create checkpoints protects against data loss, but it does not provide high availability of the filesystem. The namenode is still a single point of failure (SPOF).
- Failure & Recovery
- If it did fail, all clients—including MapReduce jobs—would be unable to read, write, or list files, because the namenode is the sole repository of the metadata and the file-to-block mapping. In such an event, the whole Hadoop system would effectively be out of service until a new namenode could be brought online.
- To recover from a failed namenode in this situation, an administrator starts a new primary namenode with one of the filesystem metadata replicas and configures datanodes and clients to use this new namenode. The new namenode is not able to serve requests until it has
- i) loaded its namespace image into memory,
- ii) replayed its edit log, and
- iii) received enough block reports from the datanodes to leave safe mode.
- On large clusters with many files and blocks, the time it takes for a namenode to start from cold can be 30 minutes or more.
- Hadoop 2 supports HDFS HA. There are a pair of namenodes in an active-standby configuration. In the event of the failure of the active namenode, the standby takes over its duties to continue servicing client requests without a significant interruption.
- Quorum Journal Manager
- The QJM is designed for the sole purpose of providing a highly available edit log, and is the recommended choice for most HDFS installations. (is a dedicated HDFS implementation)
- The QJM runs as a group of journal nodes, and each edit must be written to a majority of the journal nodes. Typically, there are three journal nodes, so the system can tolerate the loss of one of them.
- This arrangement is similar to the way ZooKeeper works, although it is important to realize that the QJM implementation does not use ZooKeeper. HDFS HA does use ZooKeeper for electing the active namenode.
- If the active namenode fails, the standby can take over very quickly (in a few tens of seconds) because it has the latest state available in memory: both the latest edit log entries and an up-to-date block mapping.
- Failover Controller
- The transition from the active namenode to the standby is managed by a new entity in the system called the failover controller.
- There are various failover controllers, but the default implementation uses ZooKeeper to ensure that only one namenode is active.
- Each namenode runs a lightweight failover controller process whose job it is to monitor its namenode for failures (using a simple heartbeating mechanism) and trigger a failover should a namenode fail.
- Graceful Failover: Failover may also be initiated manually by an administrator, for example, in the case of routine maintenance. This is known as a graceful failover, since the failover controller arranges an orderly transition for both namenodes to switch roles.
- Fencing
- In the case of an ungraceful failover, however, it is impossible to be sure that the failed namenode has stopped running. For example, a slow network or a network partition can trigger a failover transition, even though the previously active namenode is still running and thinks it is still the active namenode. The HA implementation goes to great lengths to ensure that the previously active namenode is prevented from doing any damage and causing corruption—a method known as fencing.
- The QJM only allows one namenode to write to the edit log at one time; however, it is still possible for the previously active namenode to serve stale read requests to clients, so setting up an SSH fencing command that will kill the namenode’s process is a good idea.
- Stronger fencing methods are required when using an NFS filer for the shared edit log, since it is not possible to only allow one namenode to write at a time (this is why QJM is recommended).
- Fencing Mechanisms
- includes revoking the namenode’s access to the shared storage directory
- disabling its network port via a remote management command.
- As a last resort, the previously active namenode can be fenced with a technique rather graphically known as STONITH, or “shoot the other node in the head,” which uses a specialized power distribution unit to forcibly power down the host machine.
HDFS interface
- HDFS shell
- Java API
- REST API - WebHDFS, HttpFS(standalone RESTful HDFS proxy service)
MapReduce
- MapReduce works by breaking the processing into two phases: the map phase and the reduce phase. Each phase has key-value pairs as input and output, the types of which may be chosen by the programmer. (Reduce is optional)
- Concepts
- concepts of functions called map and reduce come straight from functional programming languages where they were applied to lists of input data.
- divide and conquer - a single problem is broken into multiple individual subtasks. This approach becomes even more powerful when the subtasks are executed in parallel;
- Unlike traditional relational databases that require structured data with well-defined schemas, MapReduce and Hadoop work best on semi-structured or unstructured data.
- Hadoop Basic Data Types
- Rather than using built-in Java types, Hadoop provides its own set of basic types that are optimized for network serialization.
- These are found in
org.apache.hadoop.ioLong–>LongWritableInteger–>IntWritableString–>Text
Mapper
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 | |
- Input Splits
- Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits or just splits.
- Hadoop creates one map task for each split, which runs the map function for each record in the split.
- A good split size tends to be the size of an HDFS block (128MB).
- If the spilt size is too small, the overhead of managing the splits and map task creation is high
- If the split size is too large, then the desirable load balancing will be missing.
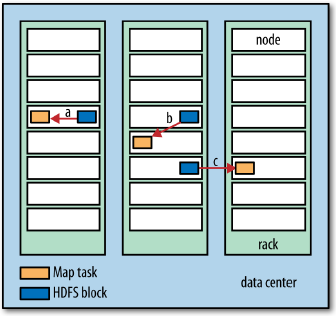
- Data Locality Optimization
- Hadoop does its best to run the map task on a node where the input data resides in HDFS, because it doesn’t use valuable cluster bandwidth. This is called Data Locality Optimization.
- Sometimes, however, all the nodes hosting the HDFS block needed for the map task are running other tasks, so the job scheduler will look for a free map slot on a node in the same rack or an off-rack node and copies the data over.
- The output of map tasks are written to the local disk, not to HDFS. Because Map output is intermediate output: it’s processed by reduce tasks to produce the final output, and once the job is complete, the map output can be thrown away. So, storing it in HDFS with replication would be overkill. If the node running the map task fails before the map output has been consumed by the reduce task, then Hadoop will automatically rerun the map task on another node to re-create the map output.
Reducer
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 | |
- Reducer is an optional function. A MapReducer job can have zero or more reducer functions.
- The input types of the reduce function must match the output types of the map function
- Data Locality Optimization
- Reduce tasks don’t have the advantage of data locality; the input to a single reduce task is normally the output from all mappers.
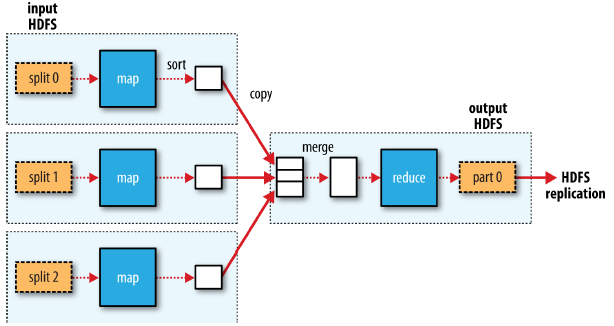
- In the present example, we have a single reduce task that is fed by all of the map tasks. Therefore, the sorted map outputs have to be transferred across the network to the node where the reduce task is running, where they are merged and then passed to the user-defined reduce function.
- The output of the reduce is normally stored in HDFS for reliability.
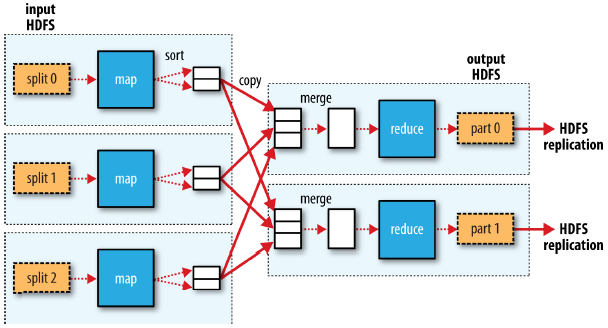
- The number of reduce tasks is not governed by the size of the input, but instead is specified independently. When there are multiple reducers, the map tasks partition their output, each creating one partition for each reduce task. There can be many keys (and their associated values) in each partition, but the records for any given key are all in a single partition. The partitioning can be controlled by a user-defined partitioning function, but normally the default partitioner—which buckets keys using a hash function—works very well.
| MapReduce data flow with single reduce task | MapReduce data flow with multiple reduce tasks |
 |
 |
Combiner
- A Combiner function helps cut down the amount of data shuffled between the mappers and reducers. But it is a not a replacement for reducer.
- For example, if the reduce function is meant to calculate the max temperature per year, then
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
- The above data can be expressed as max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
- Only functions with commutative and associative properties can be represented as combiners.
- Because the combiner function is an optimization, Hadoop does not provide a guarantee of how many times it will call it for a particular map output record, if at all.
- In other words, calling the combiner function zero, one, or many times should produce the same output from the reducer
MapReducer Job
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
1 2 | |
Hadoop Streaming
-
- Hadoop Streaming is a mechanism allowing scripting languages to be used to write map-reduce tasks
- Both Map and Reduce tasks take input from STDIN and writes output to STDOUT
- Push vs Pull model of MapReduce
YARN
- Yet Another Resource Negotiator
References
- Books
- Hadoop: The Definitive Guide by Tom White
- Hadoop Application Architectures
- The Architecture of Open Source Applications: Elegance, Evolution, and a Few Fearless Hacks by Amy Brown and Greg Wilson (Chapter 9)