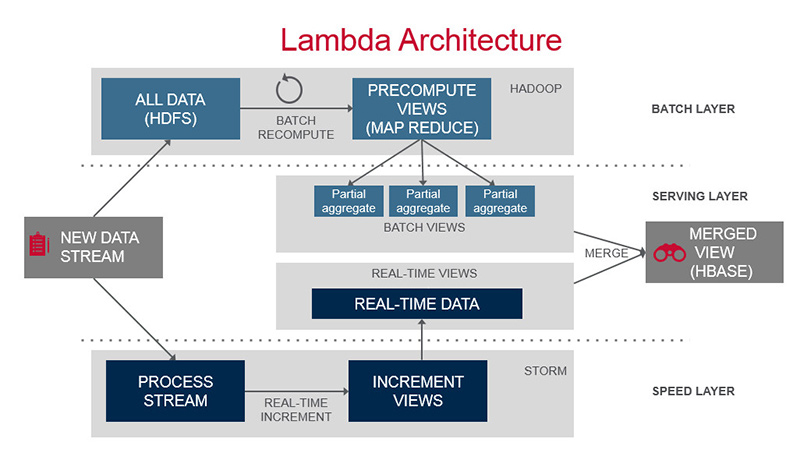
Lambda Architecture
- Data Ingestion
- Kafka
- Flume
- Scribe
- *MQ
- Serialization
- Without schema
- CSV
- With schema
- Thrift
- Avro
- Protobuffers
- Without schema
Batch Layer
- ElephantDB
- Splout
- Voldemort
- Hadoop
Speed Layer
- Cassandra
- Hbase
- Redis
- MySQL
- ElasticSearch
Serving Layer
Processing Models
Comparing Apache Storm and Apache Spark’s Streaming, turns out to be a bit challenging. One is a true stream processing engine that can do micro-batching, the other is a batch processing engine which micro-batches, but cannot perform streaming in the strictest sense. Furthermore, the comparison between streaming and batching isn’t exactly subtle, these are fundamentally different computing ideas.
Batch Processing
- Batch processing is the familiar concept of processing data en masse. The batch size could be small or very large. This is the processing model of the core Spark library.
- Batch processing excels at processing large amounts of stable, existing data. However, it generally incurs a high-latency and is completely unsuitable for incoming data.
Event-Stream Processing
- Stream processing is a one-at-a-time processing model; a datum is processed as it arrives. The core Storm library follows this processing model.
- Stream processing excels at computing transformations as data are ingested with sub-second latencies. However, with stream processing, it is incredibly difficult to process stable data efficiently.
Micro-Batching
- Micro-batching is a special case of batch processing where the batch size is orders smaller. Spark Streaming operates in this manner as does the Storm Trident API.
- Micro-batching seems to be a nice mix between batching and streaming. However, micro-batching incurs a cost of latency. If sub-second latency is paramount, micro-batching will typically not suffice. On the other hand, micro-batching trivially gives stateful computation, making windowing an easy task.