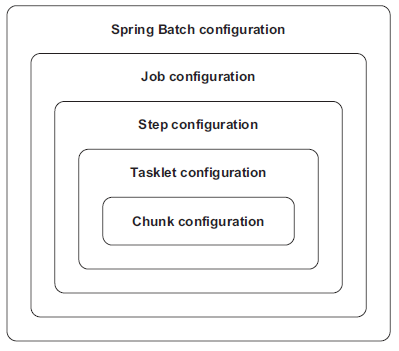
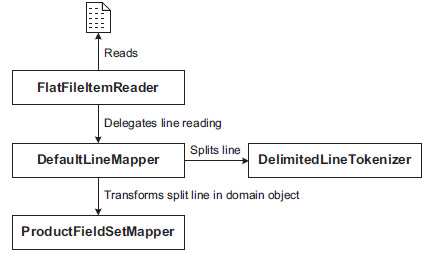
Spring Batch includes a batch-oriented algorithm to handle the execution flow called
chunk processing.
Spring Batch processes items in chunks. A job reads and writes items in small chunks. Chunk processing allows streaming data instead of loading all the data in memory. By default, chunk processing is single threaded and usually performs well, but has an option to distribute processing on multiple threads or physical nodes as well.
Spring Batch collects items one at a time from the ItemReader into a configurable-sized chunk.
Spring Batch then sends the chunk to the ItemWriter and goes back to using the ItemReader to create another chunk, and so on, until the input is exhausted.
Spring Batch provides an optional processing where a job can process (transform) items before sending them to ItemWriter. It is called ItemProcessor.
Spring Batch also handles transactions and errors around read and write operations
SPLITTING INFRASTRUCTURE AND APPLICATION CONFIGURATION FILES - Always split infrastructure and application configuration files, so that it allows to swap out the infrastructure for different environments (test, development, staging, production) and still reuse the application configuration files.
Job Attributes
id - Identifies the job.
restartable
Specifies whether Spring Batch can restart the job. The default is true.
If false, Spring Batch can’t start the job more than once; if you try, Spring Batch throws the exception JobRestartException.
incrementer
Refers to an entity used to set job parameter values. This entity is required when trying to launch a batch job through the startNextInstance method of the JobOperator interface.
The incrementer attribute provides a convenient way to create new job parameter values. Note that the JobLauncher doesn’t need this feature because you must provide all parameter values explicitly. When the startNextInstance method of the JobOperator class launches a job, though, the method needs to determine new parameter values and use an instance of the JobParametersIncrementer interface:
Specifies whether the job definition is abstract. If true, this job is a parent job configuration for other jobs. It doesn’t correspond to a concrete job configuration
parent
Defines the parent of this job.
job-repository
Specifies the job repository bean used for the job. Defaults to a jobRepositorybean if none specified.